Spark能代替Hadoop吗?

根据现有的发展,目前spark还不能完全代替Hadoop 。我们知道Hadoop包含三个组件yarn,hdfs,MapReduce,分别对应解决三个方面的问题,资源调度(yarn),分布式存储(hdfs),分布式计算(mapreudce) 。而spark只解决了分布式计算方面的问题,跟MapReduce需要频繁写磁盘不同,spark重复利用内存,大大提高了计算效率,在分布式计算方面spark大有取代MapReduce之势,而在资源调度,和分布式存储方面spark还无法撼动 。
hadoop与spark的区别是什么?
谢谢邀请!请看下面这张图:狭义的Hadoop 也就是最初的版本:只有HDFS Map Reduce后续出现很多存储,计算,管理 框架 。如果说比较的话就 Hadoop Map Reduce 和 Spark 比较,因为他们都是大数据分析的计算框架 。Spark 有很多行组件,功能更强大,速度更快 。关注我了解更多大数据分析技能 。
在hadoop和spark之间如何取舍?

其实这两个工具之间一般并不存在取舍关系 。业界一般会结合试用这两个工具 。hadoop基于集群存储和分析调度的工具包,大家常用的有hdfs,mapreduce,yarn,属于平台基础设施,主要负责海量数据存储和并行计算调度 。而spark是个大数据快速分析工具,一般实在hadoop基础上运行(虽然也可独立运行),通过hadoop的yarn调度,实现海量数据的流式处理 。
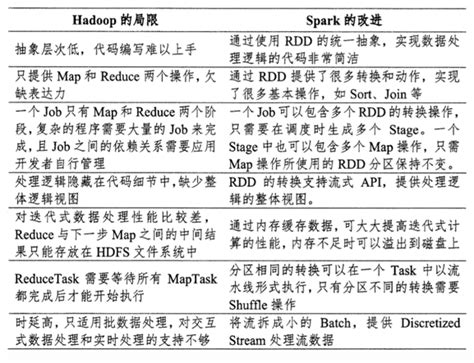
MapReduce和Spark的区别是什么?
谢邀回答首先分别来说一下两者MapReduce 是hadoop 的分布式运算编程框架核心功能将用户编写的逻辑代码和自带组件整合成一个程序,并发运行在hadoop集群是上,核心组件是mrAppmaster mapTask ReduceTaskSpark是mapReduce的替代方案,兼容HDFS、Hive,可融入hadoop的生态系统两者区别1.spark比MapReduce要快基于内存的运算,比MapReduce快100倍以上基于硬盘的运算,快10倍以上2.spark支持流式和离线两者运算MapReduce只支持离线运算3.MapReduce本身没有资源调度系统,必须运行在yarn等资源系统上spark本身集成资源调度,以standalone方式可运行在自身的Master 和worker上,也可以运行在yarn上篇幅有限就先介绍到这里,欢迎大家留言评论 。
大数据Spark技术是否可以替代Hadoop?
Spark技术从之前和当前的技术路线上看不是为了替代Hadoop,更多的是作为Hadoop生态圈(广义的Hadoop)中的重要一员来存在和发展的 。首先我们知道Hadoop(狭义的Hadoop)有几个重点技术HDFS、MR(MapReduce),YARN 。这几个技术分别对应分布式文件系统(负责存储),分布式计算框架(负责计算),分布式资源调度框架(负责资源调度) 。
我们再来看Spark的技术体系,主要分为以下:- Spark Core :提供核心框架和通用API接口等,如RDD等基础数据结构;- Spark SQL : 提供结构化数据处理的能力,分布式的类SQL查询引擎;- Streaming: 提供流式数据处理能力;- MLLib: 提供分布式机器学习常用的算法包;- GraphX : 提供图计算能力从上面Spark的生态系统看,Spark主要是提供各种数据计算能力的(官方称之为全栈计算框架),本身并不过多涉足存储层和调度层(尽管它自身提供了一个调度器),它的设计是兼容流行的存储层和调度层 。
也就是说,Spark的存储层不仅可以对接Hadoop HDFS,也可以对接Amazon S2; 调度层不仅可以对接Hadoop YARN也可以对接(Apache Mesos) 。因此,我们可以说Spark更多的是补充Hadoop MR单一批处理计算能力, 而不是完全替代Hadoop的 。【关注ABC(A:人工智能;B:BigData; C: CloudComputing)技术的攻城狮,Age:10 】 。
推荐阅读













- 圈铁耳机和动圈耳机哪个好,动铁耳机和动圈耳机的区别
- 各种电机原理动态图,电动机原理
- 中巴是哪两个国家
- 三菱报修,各位大神三菱系统显示绝对值错误和伺服25报警信息是怎么回事啊
- 楼面价和房价的公式,房子楼面价和房价如何估算
- 手机怎么玩傲剑2页游,那个动画和页游奔腾的时代落幕了
- 苹果se看电影怎么样,苹果6和se哪个好
- 饿了么 美团哪个便宜,饿了么和美团点餐哪个便宜
- 电扇和空调哪个辐射大,吹空调和吹风扇
- 一加3和htc10哪个好,iqoo3和一加8